Project Checklist
Make sure you are familiar with the rules concerning the use of Artificial Intelligence (generative AI) in teaching and exams at DTU
IMPORTANT: Ask yourselves:
“Have we remembered to look through the FAQ and description”
- This is essential, this is where all the information on the project is collected
“Have we included a project README on the GitHub Repository?”
- IMPORTANT: First header in the README has to be “Project Contributors” and then please state the student ids and matching GitHub usernames, so we know who-is-who
- Be sure to include a direct link to your presentation, e.g. the direct link to the lecture in lab 3 is:
https://raw.githack.com/r4bds/r4bds.github.io/main/lecture_lab03.html - Since we’re not putting data on GitHub, you need to let us know how to get the data
“Does our presentation follow the IMRAD structure?”
- Is the presentation created as one
qmd-file and output to a HTML? - Are the 10 presentation slides clear and concise? (Title slides does not count)
- Did we include slide numbers in the presentation?
- Are we doing good data communication via good visualisations?
- Do we present a clear overview of the data process incl. any decisions made, e.g. using a flow chart?
- Are we clearly communicating a biological insight?
- Are we following standard guidelines? Sources, references, etc.

“Does our project include all components of the data science cycle?”
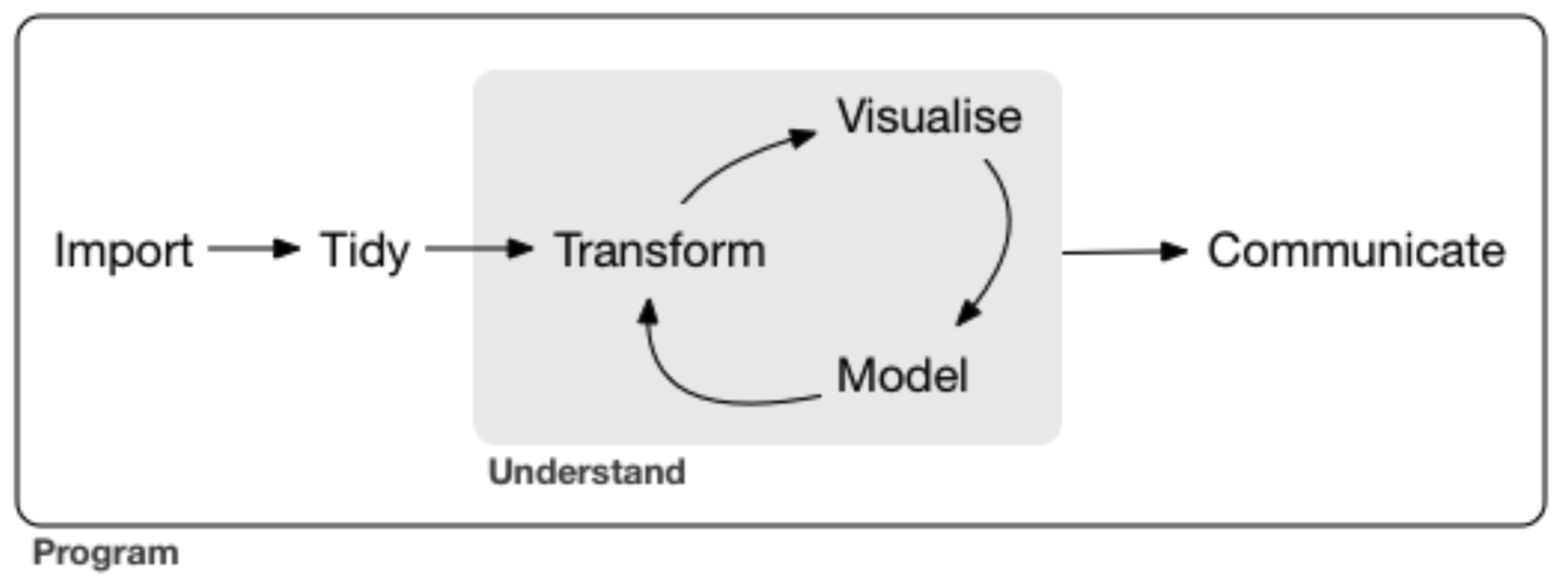
“Are we aware of and have included learning objectives as appropriate in the project?”
Check your project against the course learning objectives, as defined on the DTU course base
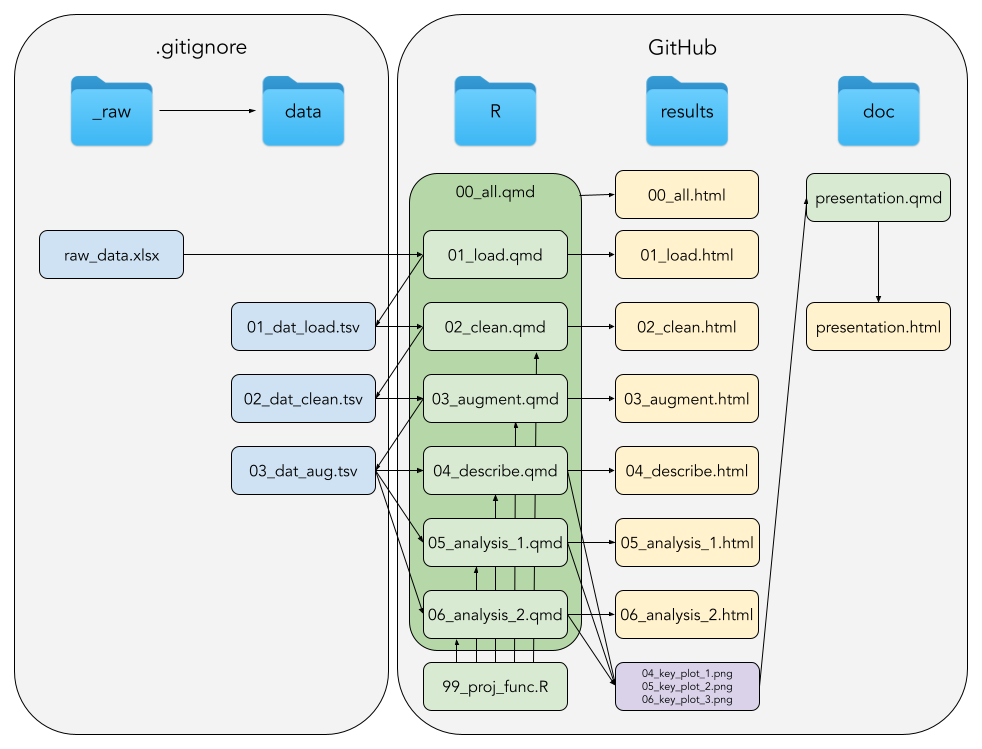
“Is our project-GitHub organised as instructed and can it run end-to-end via a”doit”?”
- A “doit” is a script, which acts as a wrapper executing other scripts. In the project organisation, what would be the
00_all.qmd-file
(Note, this is a generic representation, e.g. you do not need exactly 3 key plots nor exactly 2 analyses)
“Does ALL our code in ALL our files follow the Course Style Guide?”
- Recall what we discussed in the course on styling
- See the Course Style Guide
- E.g.:

“Are we using base-R, where we should use tidyverse-R?”
- E.g. think about the following:

“Can we explain and justify the data decisions in the project?”
- IMPORTANT: In essence it does not matter which decision you took, what really matters is your ability to explain and justify why you took that decision, e.g. decided on a particular path in your analysis
